
Mit SDKMAN! und anderen Werkzeugen Übersicht in Konfigurationen behalten – ein Erfahrungsbericht mit Howto Anleitung. Arbeiten an mehreren Projekten ist Fluch und Segen zugleich. Auf der einen Seiten bietet es Abwechslung, aber auf der anderen Seite hat man die Herausforderung seine Arbeitsumgebung so zu konfigurieren, dass sie zum jeweiligen Projekt passt. Angefangen bei der Auswahl der Versionen der eingesetzten Werkzeugen, über unterschiedliche Git Authentifizierungen und Identitäten bis hin zu unterschiedlichen Codeformatierungen. Dabei müssen die Projekte nicht unbedingt bei unterschiedlichen Kunden liegen. Manchmal haben auch Projekte innerhalb einer Firma einen unterschiedlichen Aufbau oder man arbeitet an unterschiedlichen Open Source Projekten mit.
Dieser Artikel zeigt wie verschiedene Versionen von Werkzeugen vereinfacht verwalten werden können, wie Git konfiguriert werden kann, dass es mit unterschiedlichen Authentifizierungen und Identitäten umgehen kann und wie in einem Projekt sichergestellt werden kann, dass die richtigen Codeformatierungen verwendet werden.
Verwaltung von verschiedenen Werkzeug-Versionen

Kotlin Groovy Java
Man stelle sich folgende Situation vor: Wir arbeiten in einer Firma, in der unterschiedliche JVM-Sprachen im Einsatz sind, wie z.B. Kotlin, Groovy und Java. Diese Tatsache alleine bereitet noch keine Schwierigkeit. Dieses Problem ist mit dem Download und Installation des jeweiligen SDK erledigt. Jetzt existiert aber noch die Situation, dass in den einzelnen Projekten unterschiedliche Versionen der Sprachen eingesetzt werden. Dank der Micro-Service-Philosophie „Jedes Team sucht sich seine Technologien selber aus.“ nicht unrealistisch, wenn diese Philosophie auf die Spitze getrieben wird. Damit ist die manuelle Pflege der SDKs aufwendig. In der JVM-Welt hilft uns das Werkzeug SDKMAN! dabei diese Problem in den Griff zu bekommen.
JVM-Werkzeuge mit SDKMAN! verwalten
SDKMAN! ist ein CLI-Werkzeug. Die Installation erfolgt über ein Shell-Skript:
$ curl -s "https://get.sdkman.io" | bash
$ source "$HOME/.sdkman/bin/sdkman-init.sh"
$ sdk version
SDKMAN! hilft nicht nur bei der Verwaltung von JVM-Sprachen, sondern auch bei der Verwaltung von u.a. Buildwerkzeugen und Frameworks für die JVM. Mit sdk list listet alle unterstützten Kandidaten auf. Die Installation der einzelnen Kandidaten erfolgt über die CLI:
$ sdk install groovy # installiert die letzte Version von Groovy
$ sdk install groovy 2.3.10 # installiert eine spezfische Version von Groovy
$ sdk list groovy # listet alle verfügbaren Versionen von Groovy auf
================================================================================
Available Groovy Versions
================================================================================
3.0.0-alpha-1 2.4.13 2.3.10 2.1.0
2.6.0-alpha-2 > * 2.4.12 2.3.1 2.0.8
2.6.0-alpha-1 2.4.11 2.3.0 2.0.7
2.5.0-beta-3 2.4.10 2.2.2 2.0.6
2.5.0-beta-2 2.4.1 2.2.1 2.0.5
2.5.0-beta-1 2.4.0 2.2.0 2.0.4
2.5.0-alpha-1 2.3.9 2.1.9 2.0.3
2.4.9 2.3.8 2.1.8 2.0.2
2.4.8 2.3.7 2.1.7 2.0.1
2.4.7 2.3.6 2.1.6 2.0.0
2.4.6 2.3.5 2.1.5 1.8.9
2.4.5 2.3.4 2.1.4 1.8.8
2.4.4 2.3.3 2.1.3 1.8.7
2.4.3 2.3.2 2.1.2 1.8.6
2.4.2 2.3.11 2.1.1 1.8.5
================================================================================
+ – local version
* – installed
> – currently in use
Ist eine Version nicht dabei, die benötigt wird, dann können wir diese Version manuell in SDKMAN! installieren. Dafür lade die benötigte Version von der jeweiligen Seite herunter und füge sie in SDKMAN! hinzu:
$ ls ~/.sdkman/candidates/groovy/ # hier kommen die Groovy SDK hin
2.4.12 current
$ md ~/.sdkman/candidates/groovy/2.4.14 # neuer Order für die manuelle installierte Version; hierher die manuell herunergeladenene Version kopieren
$ sdk list groovy
================================================================================
Available Groovy Versions
================================================================================
3.0.0-alpha-1 + 2.4.14 2.3.11 2.1.1
2.6.0-alpha-2 2.4.13 2.3.10 2.1.0
2.6.0-alpha-1 > * 2.4.12 2.3.1 2.0.8
2.5.0-beta-3 2.4.11 2.3.0 2.0.7
2.5.0-beta-2 2.4.10 2.2.2 2.0.6
2.5.0-beta-1 2.4.1 2.2.1 2.0.5
2.5.0-alpha-1 2.4.0 2.2.0 2.0.4
2.4.9 2.3.9 2.1.9 2.0.3
2.4.8 2.3.8 2.1.8 2.0.2
2.4.7 2.3.7 2.1.7 2.0.1
2.4.6 2.3.6 2.1.6 2.0.0
2.4.5 2.3.5 2.1.5 1.8.9
2.4.4 2.3.4 2.1.4 1.8.8
2.4.3 2.3.3 2.1.3 1.8.7
2.4.2 2.3.2 2.1.2 1.8.6
================================================================================
+ – local version
* – installed
> – currently in use
================================================================================
Die manuell installierte Version wird dann mit einem + gekennzeichnet.
Die tägliche Arbeit mit SDKMAN! sieht dann folgendermaßen aus:
$ sdk current # listet alle aktuell benutzten Kandidaten
Using:
groovy: 2.4.12
java: 8u151-oracle
maven: 3.5.2
$ sdk current groovy # listet die aktuelle benutzte Version von Groovy
Using groovy version 2.4.12
$ sdk default groovy # default version für Groovy, die temporär überschrieben werden kann
Default groovy version set to 2.4.12
$ sdk use groovy 2.4.13 # überschreibt die default version von Groovy für die aktuelle Shell Session
Using groovy version 2.4.13 in this shell.
$ sdk default groovy 2.4.13 # setzt eine neue Version als Default Version
Default groovy version set to 2.4.13
Das vereinfacht uns den Wechseln zwischen den Versionen projektübergreifend.
Konfiguration von verschiedenen Git Authentifizierungen
Die Projekte liegen meist in verschiedenen Git Repositories und die auch verschiedene Authentifizierungen benötigen. Diese Authentifizierungen können in Passwort Manager verwaltet werden. Doch es bleibt umständlich sich regelmäßig mit Benutzername und Passwort anzumelden. Gerade bei Git Repositories gibt es die Möglichkeit sich über einen SSH-Schlüssel zu authentifizieren und SSH kann so konfiguriert werden, dass es selber erkennt, welchen Schlüssel er gerade benutzen soll.
Nehmen wir an, wir haben zwei Git-Projekte, die zwei unterschiedliche Authentifizierung brauchen. Beide Projekte sind unter zwei unterschiedlichen Domänen erreichbar, example1.com und example2.com. Für jedes der beiden Projekte generieren wir jeweils ein Public/Private-SSH-Schlüssel-Paar (id_example1 und id_example2.
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/sparsick/.ssh/id_rsa): /home/sparsick/.ssh/id_example1
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/sparsick/.ssh/id_example1.
Your public key has been saved in /home/sparsick/.ssh/id_example1.pub.
The key fingerprint is:
SHA256:9XVMIDlWX/6OvAzVmqKUBm8pmNNoiFkjJZ/+RERhp/A sparsick@sparsick-ThinkPad-T460s
The key's randomart image is:
+---[RSA 2048]----+
| . +.. .oo.o|
| = o +. =.|
| . . E .. .. =|
| + o . . . o.|
| . = . S . . o|
| * + = o o o = |
| o o B o B o = .|
| + . = . + . |
| . . o |
+----[SHA256]-----+
Der private Schlüssel liegt dann in der Datei id_example1 und der öffentliche Schlüssel in der Datei id_example1.pub. Dieser öffentliche Schlüssel muss in dem jeweiligen Git-Management-System (Github, Gitlab, BitBucket) bzw Git-Server hinterlegt sein, damit die Authentifizierung via SSH funktionieren kann.
Jetzt muss in der SSH Konfiguration eingetragen werden, bei welcher Domäne welcher Schlüssel benutzt werden soll. Dafür wird, wenn nicht vorhanden, eine Datei config unter $USER_HOME/.ssh angelegt und darin wird eingetragen für welche Domäne welcher Schlüssel gilt:
Host example1.com
HostName example1.com
User git
IdentityFile ~/.ssh/id_example1
Host example2.com
HostName example2.com
User git
IdentityFile ~/.ssh/id_example2
Somit können die Git-Repositories geklont und gepusht werden, ohne Eingabe der jeweiligen Credentials.
Konfiguration und Benutzung von verschiedenen Git Identitäten
Mit Git Identitäten ist der Benutzername und E-Mail-Adresse gemeint, die bei jedem Commit als Autor und Committer eingetragen werden. Der Benutzername und die E-Mail-Adresse kann sich von Projekt zu Projekt unterscheiden. Eine herkömmliche Methode sieht folgendermaßen aus:
$ git clone git-repo
$ cd git-repo
$ git config user.name "Sandra Parsick"
$ git config user.email "sparsick@example1.com"
Diese Methode ist recht fehleranfällig, da die Anpassung der User-Konfiguration gerne vergessen wird. Im Folgenden sollen zwei Alternativen vorgestellt werden, die die Verwaltung der Git Identitäten vereinfachen. Die erste Methode basiert auf dem Git Feature „Conditional Includes“ (verfügbar ab Git Version 2.13) und die zweite Methode basiert auf einem Python Skritpt, der die Mercurial-Erweiterung „hg-persona“ für Git simuliert.
Git Feature „Conditional Includes“
Die Idee bei dieser Methode ist, dass eine Default Git-Identität und separate Git-Identitäten pro spezielle Verzeichnis definiert werden. Das bedeutet, dass jedes Repository, das in ein der speziellen Verzeichnisse geklont wird, automatisch die Git-Identität erhält, die für dieses Verzeichnis definiert wurde. Dafür muss parallel zu der Benutzer-Git-Konfigurationsdatei .gitconfig, eine weitere Git Konfigurationsdatei für jede Git Identität angelegt werden.
$ touch ~/.gitconfig_example1
$ touch ~/.gitconfig_example2
Darin werden die jeweiligen Git-Benutzer-Konfigurationen eingetragen
~/.gitconfig_example1
[user]
name = YourNameForExample1
email = name@example1.com
Danach muss in der Git Konfigurationsdatei .gitconfig noch definiert werden, für welches Verzeichnis welche Benutzer-Konfiguration angewendet werden soll.
~/.gitconfig
[user]
name = defaultName
email = default@email.com
[includeIf „gitdir:~/workspace_example1/“]
path = .gitconfig_example1
[includeIf „gitdir:~/workspace_example2/“]
path = .gitconfig_example2
Somit haben alle Repositorys, die unter dem Verzeichnis ~/workspace_example1 geklont werden, haben automatisch die Git Identität, die in der .gitconfig_example1 konfiguriert wurde. Alle Repositories, die unter dem Verzeichnis ~/workspace_example2 geklont werden, nehmen entsprechend die Git Identität aus .gitconfig_example2
git-persona – Hg-persona für Git
Die Idee hinter „git-persona“ ist, dass die Git-Identität individuell für jedes Repository konfigurierbar sein soll. Es ist so gesehen ein Ersatz für die git config user.* Befehlskette.
„git-persona“ wird über PyPi installiert.
$ sudo apt-get install pip # if PyPI isn't install
$ pip install ws.git-persona
Die Git-Identitäten werden in der Benutzer Git Konfigurationsdatei .gitconfig folgendermaßen definiert:
~/.gitconfig
[persona]
example1 = YourNameForExample1
example2 = YourNameForExample2
Die einzelnen Git-Identitäten können dann im jeweiligen Git-Repository mit „git-persona“ gesetzt werden.
$ git-persona -n example1
Setting user.name="YourNameForExample1", user.email="name@example1.com"
Sicherstellung der richtigen Codeformatierung
Jedes Projekt hat sein eigenen Stil wie die Codeformatierung aussehen soll. Und wenn auch innerhalb eines Team oder Firma eine projekt-übergreifend einheitliche Codeformatierung existiert, präferiert jeder Entwickler einen anderen Editor bzw. IDE. Editor bzw. IDE-übergreifend die Codeformatierung zu pflegen, wird mit der Zeit sehr mühselig. Auch stets im Hinterkopf zu behalten, dass beim Projektwechsel in der IDE oder Editor die Codeformatierung geändert werden muss, gelingt nicht immer. Dieses Dilemma möchte das Werkzeug EditorConfig auflösen. Die Idee ist, dass in dem Projekt neben dem Sourcecode auch die Einstellungen für die Codeformatierung gespeichert wird und und das Ganze Editor- bzw. IDE-neutral. Über Plugins importieren dann die Editoren bzw. die IDEs die Einstellung für die Codeformatierung spezifisch für das jeweilige Projekt. Einige Editoren und IDEs unterstützen EditorConfig nativ. Auf der Homepage von EditorConfig gibt es eine Übersicht über alle Editoren und IDEs, die entweder EditorConfig nativ oder über ein Plugin unterstützen.
Die Konfigurationsdatei von EditorConfig, .editorconfig wird im Root-Verzeichnis des Projektes abgelegt (siehe Abbildung).
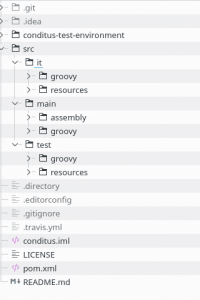
Die Konfigurationen werden im ini-Format beschrieben. Die Konfigurationen werde in Sektionen gruppiert. Die Sektionen definieren für welchen Dateityp die Konfigurationen gelten sollen (Beispiele: [*] für alle Dateitypen, [*.{java,groovy}] für Java- und Groovy-Dateien). Innerhalb dieser Sektionen wird dann die Einstellungen wie Zeichensatz (charset), Einrückungen (indent_style, indent_size) etc. Eine detaillierte Liste mit Einstellmöglichkeiten findet sich im EditorConfigs Wiki
# Sample file from http://EditorConfig.org
# EditorConfig is awesome: http://EditorConfig.org
# top-most EditorConfig file
root = true
# Unix-style newlines with a newline ending every file
[*]
end_of_line = lf
insert_final_newline = true
# Matches multiple files with brace expansion notation
# Set default charset
[*.{js,py}]
charset = utf-8
# 4 space indentation
[*.py]
indent_style = space
indent_size = 4
# Tab indentation (no size specified)
[Makefile]
indent_style = tab
# Indentation override for all JS under lib directory
[lib/**.js]
indent_style = space
indent_size = 2
# Matches the exact files either package.json or .travis.yml
[{package.json,.travis.yml}]
indent_style = space
indent_size = 2
Hast du andere Tipps und Tricks? Dann schreib ein Kommentar.
2 Kommentare
[…] Meinen liebsten Installationsweg für Groovy habe ich gefunden, als ich ein Tool gesucht habe, um zwischen Versionen meiner JVM umschalten zu können. Gelandet bin ich bei [sdkman](https://sdkman.io/), einem CLI-Tool, mit dem man eine Menge SDKs installieren und zwischen ihren Versionen hin- und herschalten kann. Sandra hat das sdkman hier auch schon angesprochen. […]
[…] https://blog.nevercodealone.de/effizienteres-arbeiten-an-mehreren-projekten/ […]